
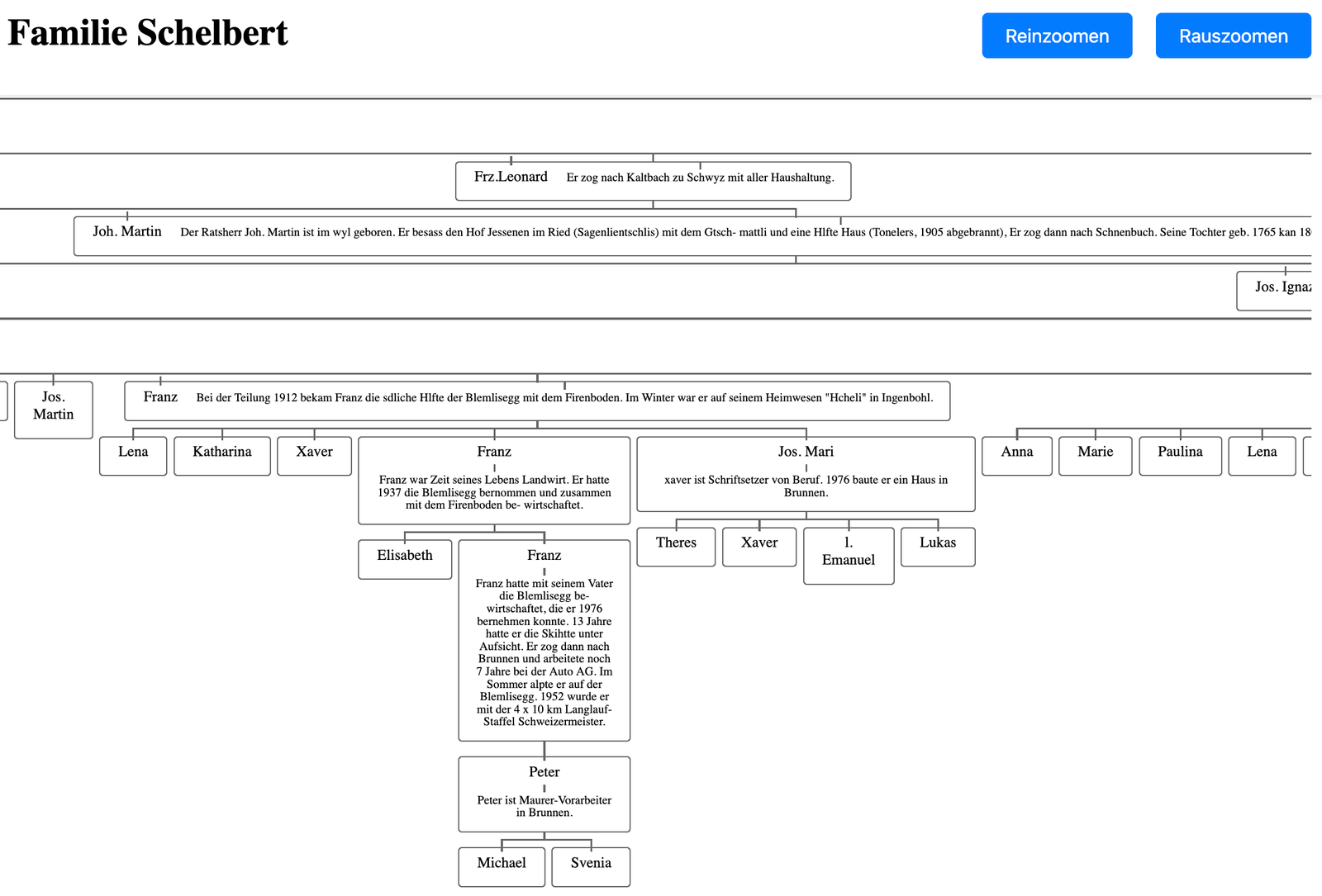
Ancestree unser Projekt aus dem Modul Computer Vision Tim hat dafür das Buch.mit seinem gesamten Stammbaum eingescannt. Das Buch handelt von der Familie Schelbert aus dem Muothatal. Darin sind alle Vorfahren aufgelistet seit dem 16. Jh. Um den Stammbaum extrahieren und darstellen zu können haben wir die eingescannten Seiten von PDF zu JPG umgewandelt. Und die einzelnen Seiten dann mithilfe von PyTesseract weiterverarbeitet.
Weitere Projektinfos
Viel Spaß mit dem Video 🍿
Dieses Projekt ist entstanden in Zusammenarbeit mit:Erarbeitet im Rahmen der Vorlesung “Computer Vision & Artificial Intelligence”, während meines Studiums in AI/ML an der Hochschule Luzern
Mit PyTesseract haben wir Bounding-Boxes erstellt. Diese haben wir dann einem “Feld-Typ” zugeordnet. Mithilfe eines selbstgeschriebenen Matching Algorithmus konnten wir dann die Zuordnungen bestimmen, welche Personen ist in welchem Jahr geboren? Wer sind die Vorfahren? Wer die Kinder? etc. daraus haben wir ein JSON Objekt gebaut, welches wir dann nutzen konnten, um den Stammbaum darzustellen.
Wir wollten erst Apache eCharts für die Darstellung verwenden, aber es waren schlicht und einfach zuviele Nodes bzw. Personen, weshalb wir uns dann für eine klassische “Stammbaum Darstellung” entschieden haben. Man muss viel scrollen, kann dafür spezifische Personen mit CTRL + F finden und kann die Pfade sauber absuchen.
